
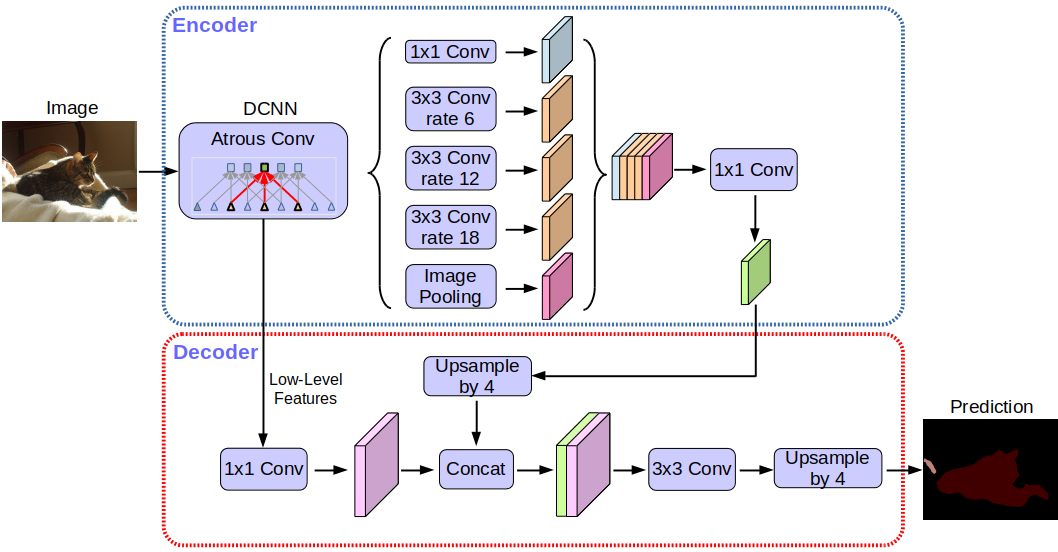
Команда исследователей Google Research объявила о выпуске последней и наиболее эффективной модели семантической сегментации изображений DeepLab-v3+ с открытым исходным кодом. Эта технология, использующая нейронные сети, позволяет проанализировать изображение, разбить его на отдельные части и определить, какой объект относится к тому или иному участку на снимке. Примером такой технологии является портретный режим фотосъёмки в смартфонах Pixel с эффектом размытия фона.
Модель семантической сегментации изображений DeepLab-v3+, реализованная средствами библиотеки Tensorflow, построена на основе мощной архитектуры сверхточной нейронной сети (CNN). Её использование позволит сторонним разработчикам внедрять возможности в своих продуктах, где требуется точный анализ и идентификация объектов.

По словам представителей Google, повсеместное использование глубокого машинного обучения на порядок улучшили качество сегментации изображений, которое достигло невероятного уровня точности. В компании надеются, что её наработки в этой области разделят и другие исследователи в различных отраслях.
После опубликования этой новости в блоге Google Research, многие зарубежные издания поспешили сообщить, что поисковый гигант открыл исходные коды портретного режима съёмки в Pixel 2 и Pixel 2 XL. Но это не совсем так, DeepLab-v3+ — гораздо более глобальная технология, отдельные функции которой применяются в ПО смартфонов Google.
