Вчера, 29 апреля, французский стартап Mistral AI представил новую версию своей большой языковой модели Medium 3.5, которая демонстрирует приличную производительность и точность генерации при относительно скромных «размерах». Суть в том, что данная LLM содержит всего 128 миллиардов параметров — по современным меркам, когда у DeepSeek-V4-Pro, например, 1,6 триллиона параметров, это выглядит не очень впечатляюще. Но есть важный момент — DeepSeek построена на архитектуре Mixture of Experts, когда во время инференса задействуется всего 49 миллиардов активных параметров из всей базы, тогда как Medium 3.5 использует все доступные параметры.
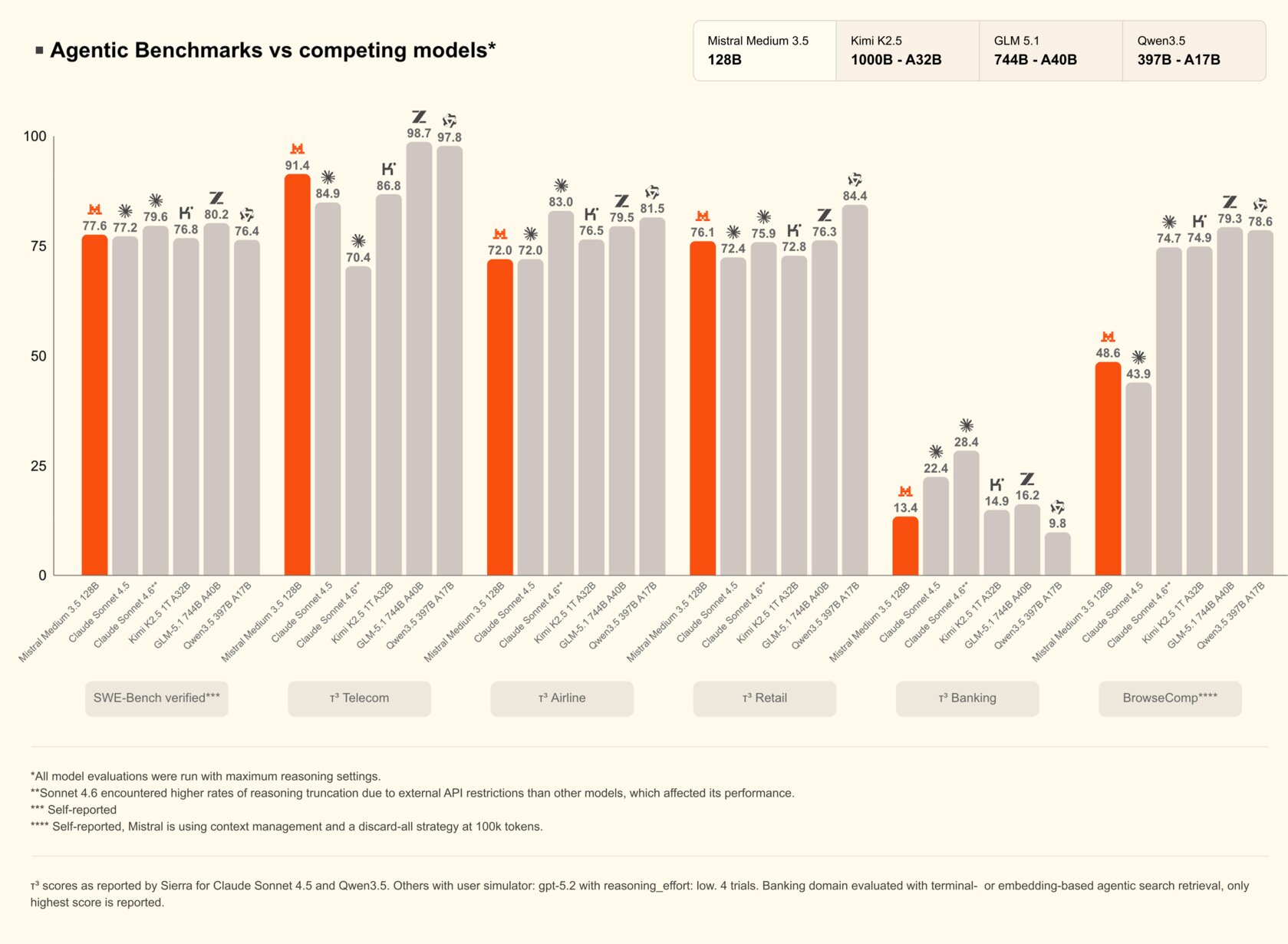
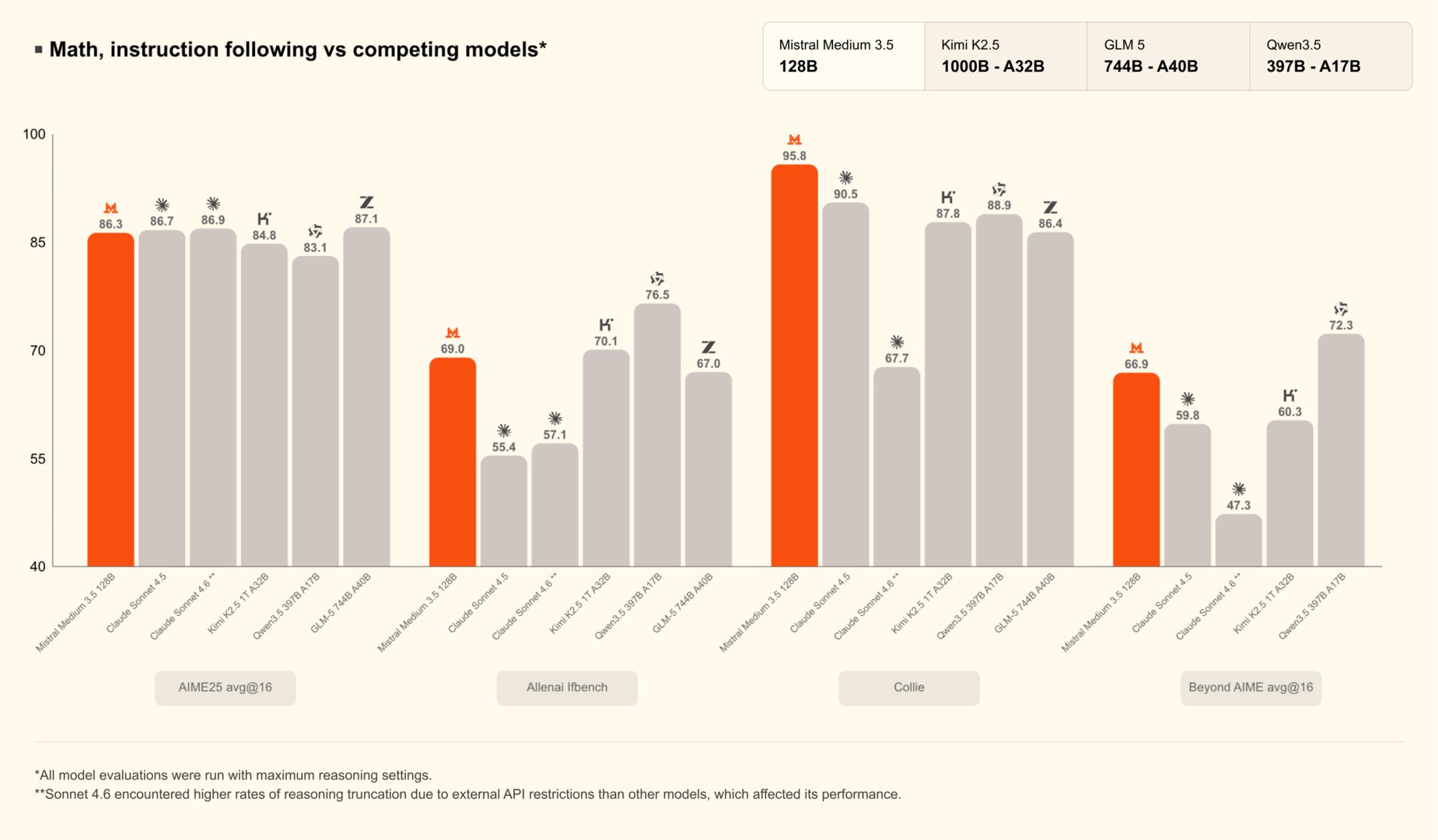
Это позволяет новой модели демонстрировать достойные результаты на фоне куда более громоздких LLM. Например, в бенчмарке, заточенном под математику, Medium 3.5 набирает 86,3 балла против 83,1 баллов у Qwen3.5, хотя у конкурирующей модели имеется 397 миллиардов параметров. Более того, новинка обходит Kimi K2.5 с 1 триллионом параметров и тягается с GLM 5 на 744 миллиарда. В результатах бенчмарков упоминается и Clause Sonnet 4.5 — закрытая модель от Anthropic, которую представили в сентябре 2025 года. Это не самая свежая разработка американского стартапа, но французы в данном случае, видимо, хотели показать, что могут тягаться с закрытыми моделями лидеров рынка.
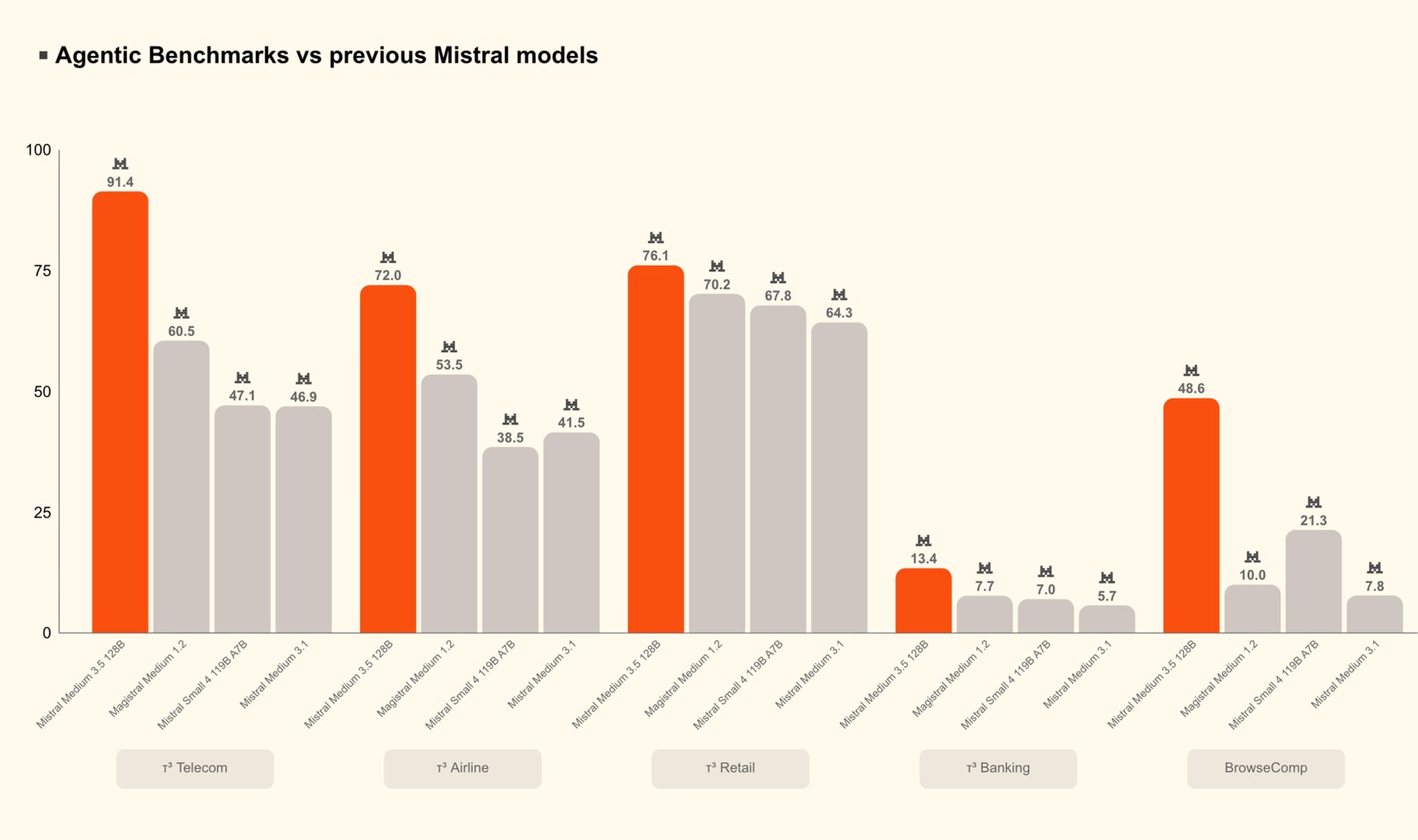
Но куда важнее прогресс Medium 3.5 по сравнению с предыдущими версиями больших языковых моделей компании Mistral AI — в определённых задачах прирост производительности действительно впечатляющий. Например, в агентских бенчмарках новинках обходит Medium 3.1 в полтора-два раза. А в бенчмарке BrowseComp новинка оказалась лучше в несколько раз. При этом разработчики отмечают, что новая версия модели была разработана специально для задач с длительным горизонтом планирования — это то, на чём делает акцент Anthropic, например. В результате ИИ лучше выполняет сложные агентские задачи, управляя функциями системы пользователя из облака.
И, что довольно важно для энтузиастов, Medium 3.5 выпускается в виде открытых весов под модифицированной лицензией MIT. Кроме того, разработчики делают акцент на том, что скромные размеры модели позволяют запускать необходимые приложения и сервисы на собственном сервере без сложных конфигураций — нужна система всего на четыре графических процессора. Это куда проще, чем в случае с моделями на триллионы параметров, для которых нужно гораздо больше быстрой памяти и вычислительных ресурсов.