Представлены DeepSeek-V3.2 и DeepSeek-V3.2-Speciale: эффективное мышление и оптимизация под агентов

Компания DeepSeek представила обновление своих языковых моделей — V3.2 и V3.2-Speciale. Они сочетают высокую вычислительную эффективность с многоэтапное рассуждение и оптимизацию под работу ИИ-агентов.
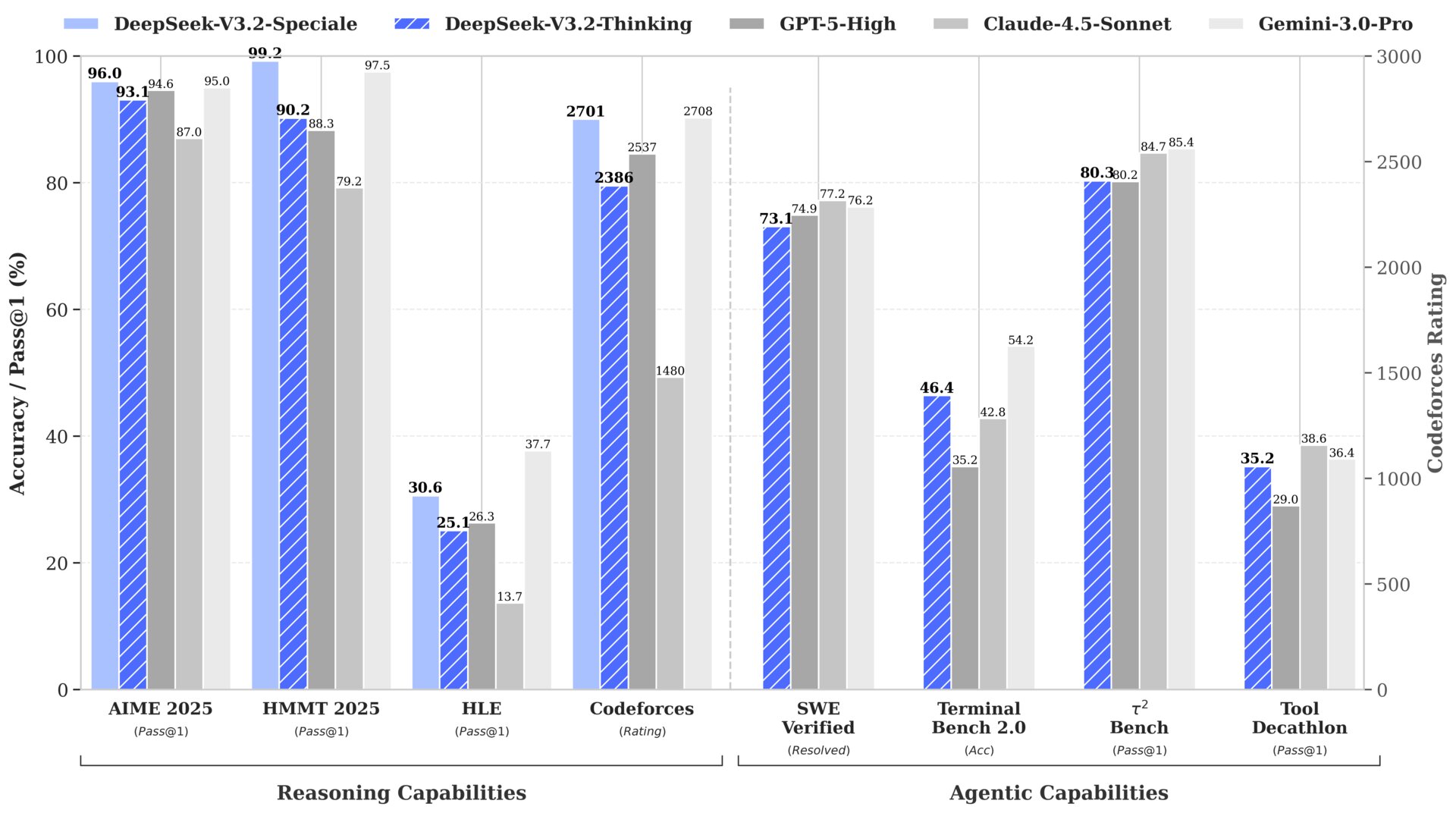
Модель DeepSeek-V3.2 пришла на смену экспериментальной версии V3.2-Exp, она получила обновлённый набор данных, оптимизированный под задачи сложного рассуждения. Это первое поколение DeepSeek, в котором реализовано встроенное «мышление» при работе с инструментами — модель способна проводить рассуждения прямо в процессе выполнения операций. Версия Speciale представляет собой усовершенствованный вариант, предназначенный исключительно для задач повышенной сложности с глубоким рассуждением. Эта модель ориентирована на агентные сценарии, требующие длинных цепочек действий, продуманного планирования и пошагового поиска решений. По словам разработчиков, Speciale демонстрирует лучшие результаты на математических олимпиадах и различных ИИ-соревнованиях.
В новых моделях можно выделить три ключевые технические достижения:
- DeepSeek Sparse Attention (DSA) — эффективный механизм внимания, который существенно снижает вычислительную сложность, сохраняя производительность в сценариях с длительным контекстом.
- Масштабируемая платформа обучения с подкреплением.
- Масштабный конвейер синтеза агентных задач, который систематически генерирует обучающие данные.
DeepSeek-V3.2 демонстрирует производительность, сравнимую с GPT-5, а DeepSeek-V3.2-Speciale превосходит GPT-5 и показывает эффективность рассуждений на уровне Gemini-3.0-Pro. Разработчики вносят существенные изменения в шаблон чата по сравнению с предыдущими версиями. Они включают обновлённый формат вызова инструментов и возможность «думать с помощью инструментов».
DeepSeek V3.2 уже доступна в чате DeepSeek, на сайте и через API. Версия Speciale пока работает только по API.