
Одну из проблем ИИ-моделей относят к сфере обучения — возможность сгенерировать сочинения и подобные работы вместо того, чтобы писать их самим, массово привлекает школьников и студентов. Проблема в том, что распознать сгенерированный текст трудно или вообще нельзя. Видимо, для борьбы с этим (вслед за объявлением о тестировании водяных знаков на сгенерированных изображениях) разработчики ChatGPT начали встраивать в текст специальные невидимые символы.
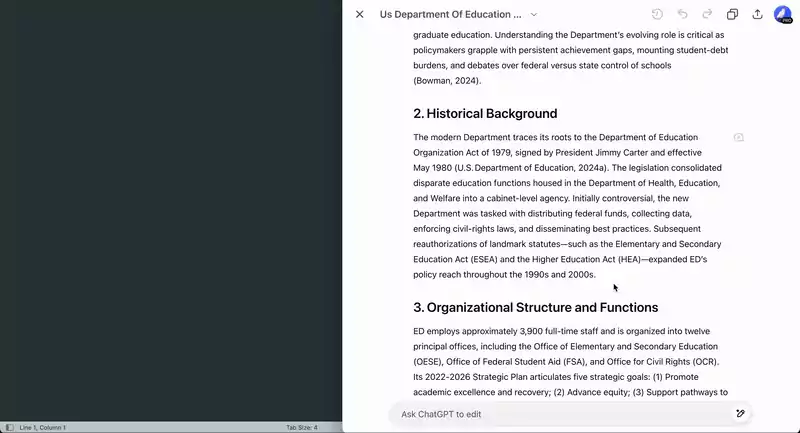
Эти невидимые символы представляют собой специальные Unicode-коды (например, неразрывного пробела), которые незаметны человеческому глазу, но видны в специальных редакторах. Например, они отображаются в популярном текстовом редакторе Sublime Text или в онлайн-инструментах.
В блоге Rumi (сотрудники этой компании заметили это одними из первых) сообщают, что ChatGPT стал поступать вышеописанным образом только в новых моделях o3 и o4-mini при генерации длинных ответов (например, на запрос «напиши полное эссе о Департаменте образования»). Но личный опыт автора этой новости несколько иной — невидимые символы встраиваются и в короткие ответы, если генерируемый текст похож на читинг со стороны пользователя. Похоже, что сейчас это работает только с ответами на английском языке.

На данный момент разработчики ChatGPT нигде не сообщали об этом нововведении — вероятно, специально, чтобы о нём знало как можно меньше людей и, соответственно, такие водяные знаки не удалялись (а стираются они в любом текстовом редакторе). В Rumi видят это временной мерой со стороны OpenAI, ведь общественность рано или поздно массово узнает о таком поведении нейросетей, с которым легко бороться.
В будущем разработчикам ничего не помешает отказаться от этого новшества, как когда-то они тихо закрыли свой сервис для определения сгенерированных текстов (который работал с крайне низкой точностью).
