Сколько вреда атмосфере Земли наносят различные ИИ: учёные провели исследование

Группа учёных из Центра цифровых наук и искусственного интеллекта в Мюнхене (Munich Center for Digital Sciences and AI) и Университет прикладных наук Мюнхена (HM Hochschule München University of Applied Sciences) провела весьма интересное и актуальное в наше время исследование. В рамках данной работы была составлена всесторонняя оценка экологической «стоимости» больших языковых моделей путём анализа их производительности, объёма используемых токенов и выбросов CO2-эквивалента (условная единица измерения, при помощи которой принято оценивать выбросы парниковых газов и их воздействие на климат планеты) на примере 14 моделей с числом параметров от 7 до 72 миллиардов.
«По оценкам специалистов, генеративные модели искусственного интеллекта, включая LLM, потребляют около 29,3 ТВтч энергии в год — это сопоставимо с общим потреблением энергии в Ирландии, например. При этом лишь незначительная часть исследований LLM затрагивают вопрос углеродного следа или воздействия ИИ на окружающую среду», — написал Алекс Де Врис (Alex de Vries) в статье «Растущий энергетический след искусственного интеллекта» (The growing energy footprint of artificial intelligence).
По итогам проведения весьма масштабной серии тестов учёные пришли к весьма ожидаемым выводам — технологии на базе искусственного интеллекта наносят существенный вред экологии.
Результаты тестов
Перед тем, как соотносить поведение больших языковых моделей с их энергопотреблением и соответствующими выбросами в CO2-эквиваленте, сначала стоит представить «сырые» результаты выполнения поставленных задач, которые лежат в основе всех дальнейших анализов данных. Собственно, в рамках исследования мы оцениваем точность каждой языковой модели на 500 вопросах из набора MMLU в двух сценариях — фазе с ограниченным выбором из нескольких вариантов ответов и фазе свободного ответа, результаты которых затем оцениваются при помощи OpenAI o4-mini.
На «Рисунке 1» указано количество правильных ответов, которое каждая из моделей дала по пяти предметным областям MMLU в обоих режимах. Сравнивая процент успеха в различных областях знаний и масштабами моделей — от 7 до 72 миллиардов параметров — мы пришли к выводу, что более крупные модели стабильно показывают более высокие результаты.
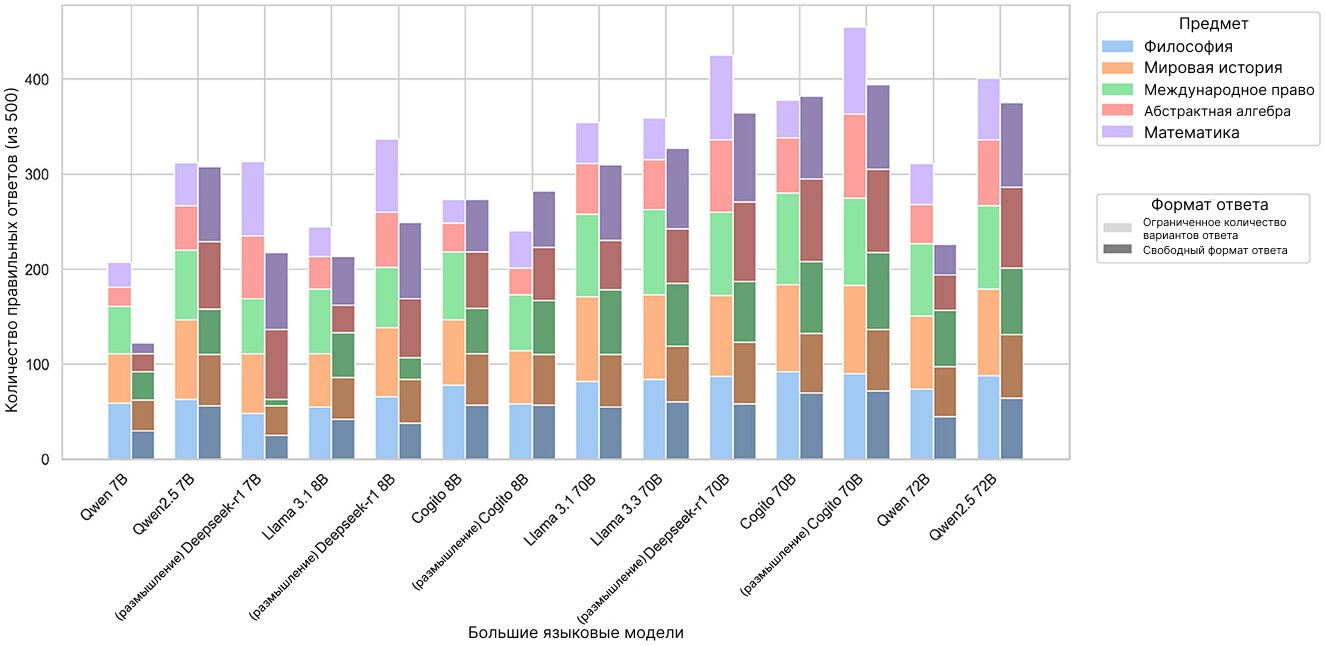
В режиме ответов с ограниченным количеством вариантов ответов лидирует «рассуждающая» большая языковая модель Cogito 70B — она продемонстрировала 91,0% правильных ответов. За ней следует модель Deepseek R1 70B (тоже с продвинутыми возможностями в области рассуждения) с результатом 85,0% и модель Qwen 2.5 72B с результатом 80,2%.
В режиме свободного ответа та же версия «рассуждающей» модели Cogito занимает первое место с 78,8%, лишь немного опережая стандартный текстовый режим Cogito 70B (76,4%) и Qwen 2.5 72B (75,0%). Среди компактных языковых моделей с 7-8 миллиардами параметров Deepseek R1 8B дала правильные ответы на вопросы в режиме с ограниченным количеством вариантов ответов в 67,4% сценариев и 49,8% — в режиме свободного ответа. Для сравнения — самая «слабая» среди компактных моделей Qwen 7B ответила правильно только в 41,4% случаев с несколькими ответами и в 24,4% — в свободном режиме.
Если же рассматривать результаты по отдельным предметам, то в режиме ограниченного набора вариантов лучший результат модели показывают по школьному курсу всемирной истории — в среднем 76,3% правильных ответов на модель. А худший — по абстрактной алгебре, где средний процент правильных ответов составляет 51,4%. В режиме свободного ответа наилучшие результаты были достигнуты по школьной математике (69,4%), а худшие — по философии (52,1%).
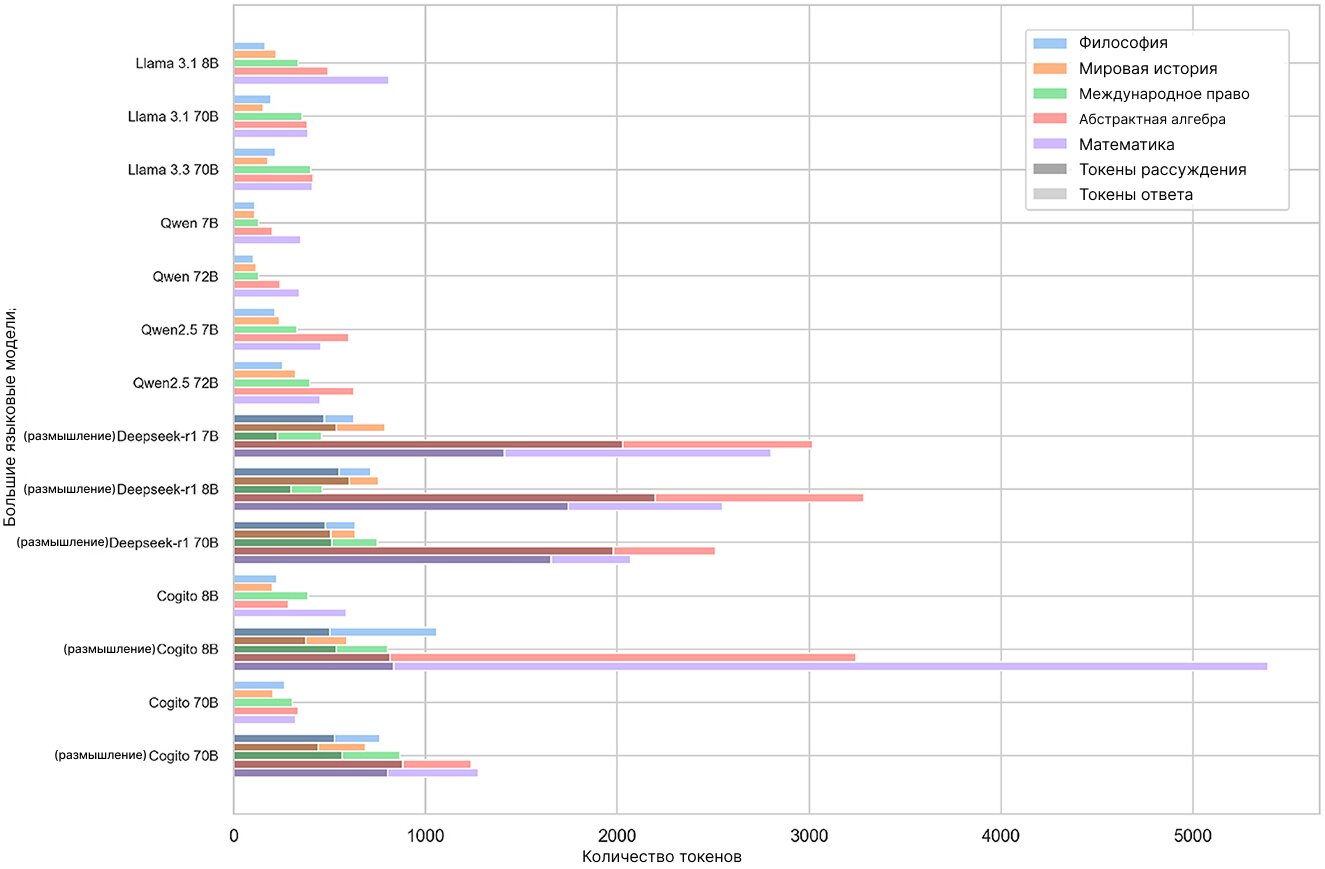
В дополнение к точности различных языковых моделей мы также анализируем количество токенов, затраченных каждой из моделей в ходе генерации ответов на 500 вопросов MMLU. Токен — это единица текста (слово, часто слова или отдельный символ), которая преобразуется в числовое представление, чтобы большая языковая модель могла её обработать. Мы отделили токены ответа (токены, составляющие финальный ответ модели) и токены размышлений (дополнительные токены, генерируемые моделями с поддержкой «рассуждений» для выдачи ответа). Для каждой из LLM указаны отдельные средние значения токенов ответа и токенов рассуждений.
В режиме с выбором из ограниченного числа ответов модели в среднем генерировали 37,7 токена ответа на вопрос, в то время как модели с рассуждениями требовали дополнительно 543,5 токена рассуждений. Стоит отметить, что модели генерировали для вопросов по математике уровня средней школы самые длинные ответы (в среднем 83,3 токена), тогда как абстрактная алгебра вызывала наибольшую когнитивную нагрузку — в среднем 865,5 токенов размышления.
В свободной форме ответа средняя длина ответов увеличилась до 435,2 токена — самые короткие ответы в этом режиме были у модели Qwen 2.5 72B в разделе философии, а самый длинный единичный вывод сгенерировала модель Cogito 8B (с «размышлениями») по абстрактной алгебре — 37 575 токенов. Среднее количество токенов размышлений на одну сессию рассуждения составляло 859,2 токена. При этом были сценарии с нулевыми токенами размышлений, когда промежуточный текст не требуется (к примеру, в случае с Cogito 70B и вопросами по истории), а максимальная нагрузка на рассуждение была зафиксирована у модели Deepseek R1 7B опять же при генерации ответа на вопрос по абстрактной алгебре — 6 716 токенов.
На «Рисунке 2» представлено распределение количества токенов для каждой модели по всем пяти параметрам в режиме свободного ответа.
На «Рисунке 3» изображены общие выбросы в CO2-эквиваленте, выраженные в граммах, необходимые большим языковым моделям для обработки полного набора из 500 вопросов MMLU как в первой, так и во второй фазах.
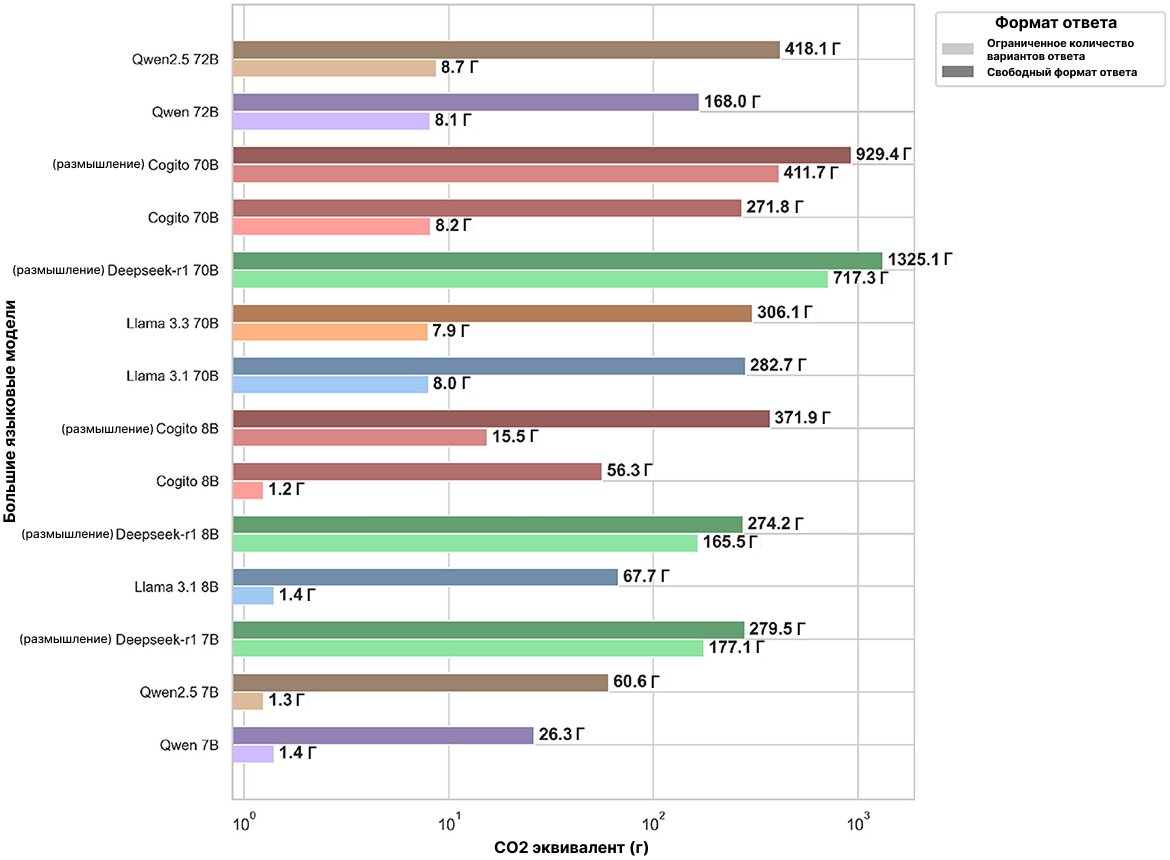
В фазе с выбором из ограниченного количества ответов выбросы варьировались от всего 1,25 грамма CO2 для модели Cogito 8B до 717,31 грамма CO2 для модели Deepseek-R1 70B. Варианты больших языковых моделей с поддержкой рассуждений генерировали значительно больше выбросов, чем их стандартные аналоги (например, Cogito 70B с рассуждением выделяет 411,72 грамма, тогда как Cogito 70B по умолчанию выделяет всего 8,2 грамма), при этом крупные модели (70-72B) стабильно выделяют от 100 до 700 граммов, тогда как компактные модели (7-8B) в среднем генерировали менее 180 граммов.
В фазе свободных ответов разброс стал ещё шире — от минимальных 26,26 грамма CO2 в случае с Qwen 7B до максимальных 1325,12 грамма в случае с Deepseek-R1 70B. И, естественно, режимы рассуждения приводили к повышению выбросов в среднем в 4-6 раз по сравнению со стандартными режимами. Например, Cogito 8B с рассуждением расходовал 371,87 грамма против 56,30 грамма в стандартном режиме. Кроме того, модели с большим количеством параметров (70-72B) производили на несколько сотен граммов CO2 больше, чем их аналоги, но на 7-8 миллиардов параметров. Например, модель Qwen2.5 72B выделяет 418,12 грамма против 60,63 грамма у Qwen2.5 7B. Эти тенденции подчёркивают экологические издержки, связанные с масштабом этой модели и глубиной их рассуждений.
При сравнении совокупных выбросов CO2 и общей точности по всем 1000 вопросам («Рисунок 4») можно заметить очевидные связи между масштабом модели, глубиной рассуждений и экологической «ценой». Самая компактная модель Qwen 7B производит всего 27,7 грамма CO2, что является самым низким показателем, но LLM демонстрирует точность всего 32,9%. Напротив, самая крупная модель рассуждения Deepseek-R1 70B производит 2042,4 грамма CO2, но демонстрирует точность на уровне 78,9%.
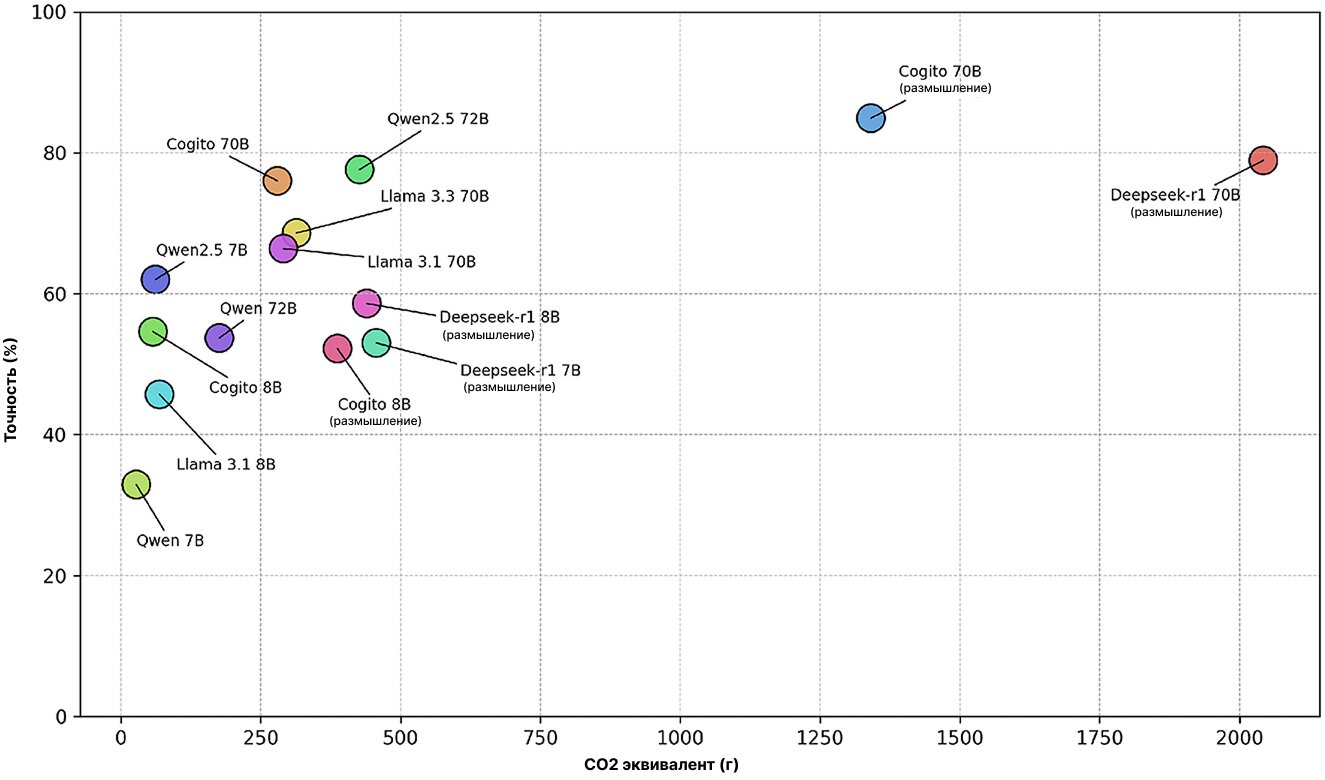
Примечательно, что 12 из 14 протестированных моделей выделяют менее 500 граммов CO2, однако ни одна из них не способна превысить точность ответов в 80%. Кроме того, модель Cogito 70B с поддержкой рассуждений выбрасывает 1341,1 грамма CO2 — на 34,3% меньше, чем Deepseek-R1 70B с тем же объёмом параметров, при этом обеспечивая точность в 84,9% — на 7,6% выше, чем у аналога без функции рассуждений.
Аппаратная платформа
Все выбросы в рамках данного исследования оценивались при использовании конкретного аппаратного обеспечения и энергетического профиля — речь идёт о графическом ускорителе NVIDIA A100 с 80 ГБ видеопамяти и коэффициентом выбросов 480 граммов CO2/кВтч. Полученные значения в значительной степени зависят от используемой инфраструктуры и локальной энергосети — при иных конфигурациях оборудования или других базовых показателях выбросов результаты могут существенно отличаться.
Это перевод статьи Frontiers.