
Над автоматическими переводчиками начали работать ещё в середине XX века. После одного из успешных экспериментов в газетах писали, что скоро ручной перевод будет не нужен — переводчиков-людей заменят машины. С тех пор прошло 70 лет, но автоматический перевод всё ещё делает глупые и грубые ошибки. Что с ним не так?
Почему раньше онлайн-переводчиками было невозможно пользоваться без смеха
Ещё 5-7 лет назад любой онлайн-переводчик выдавал наборы фраз, в которых с трудом можно было уловить смысл текста. Если вы переводили с иностранного языка на родной, то это можно было исправить. Но при переводе с родного языка на иностранный сразу было видно, что поработал Google Translate или другой переводчик. Виной всему была сама технология — статистический машинный перевод.
Чтобы лучше понимать, почему переводчики раньше были такими топорными, давайте коротко пройдёмся по основным технологиям, которые использовались для обработки текстов на разных языках. Работа над автоматизированными системами перевода начались ещё в середине XX века. Сначала в них использовали правила, которые составляли лингвисты. Их количество было огромным, а результат работы всё равно провальным. Переводчики не справлялись с многозначными словами и не понимали устойчивые выражения.
Разочарование от первых систем перевода было таким большим, что почти 30 лет никто не вкладывал в эту сферу большие деньги. Всё изменилось в начале 1990-х годов, когда одна из исследовательских групп компании IBM разработала новую переводную модель. Ключевая идея технологии — концепция канала с ошибками, которая рассматривает текст на языке A как зашифрованный текст на языке Б. Задача переводчика — расшифровать фрагмент.
Основой для модели IBM стали документы канадского правительства, написанные на английском и французском языках. Именно эта пара стала первой, над которой стали работать специалисты. Они собрали вероятности для всех сочетаний слов определённой длины на одном языке и вероятности для соответствия каждого из таких сочетаний сочетанию на другом языке. Фактически алгоритм пытается найти самую частотную фразу на языке А, которая имеет хоть какое-то отношение к фразе на языке Б.
Система статистического машинного перевода IBM стала прорывной. С появлением интернета у специалистов появился доступ к огромному количеству данных на разных языках. Исследователи сконцентрировались на сборе корпуса параллельных текстов — одинаковых документов, написанных на разных языках. Это протоколы международных организаций, научные материалы, публицистика. При их изучении устанавливалось соответствие предложений и слов. Например, при сравнении текстов на разных языках система понимает, что «cat» и «кошка» — вероятные переводы друг друга.
В статистической модели машинного перевода каждому слову и фразе соответствует числовой идентификатор, который определяет частоту использования в языке. При переводе предложение разбивается на независимые части. Для каждого элемента этого массива подбирается потенциальный перевод. Затем система собирает несколько вариантов предложения на другом языке и выбирает из них оптимальный с точки зрения сочетаемости слов.
Но машинный перевод всё равно работал неидеально. Главная проблема состояла в том, что слова и фразы переводились независимо. Переводчики не учитывали контекст и даже не согласовывали части предложения. Другая проблема — нехватка параллельных текстов. Из-за этого сложно установить соответствие. В качестве универсального связующего языка в статистическом машинном переводе используется английский.
Если параллельных текстов между двумя языками мало, то перевод выполняется в два этапа. Например, при переводе с русского на малайский порядок будет такой: сначала с русского на английский, затем с английского — на малайский.
Результат получается близким к натуральным, но даже в такой короткой цепочке могут возникнуть ошибки из-за многозначных слов.
Нейросети сделали перевод заметно лучше — иногда его сложно отличить от человеческого
Нейросети тоже анализируют массив параллельных текстов — в этом смысле ничего не изменилось. Но вместо простых идентификаторов при нейросетевом подходе используется векторное представление. Каждый вектор состоит из чисел, которые характеризуют слово по лексическим и семантическим признакам.
При статистическом машинном переводе исходное предложение разбивается на слова и фразы, после чего система ищет для них соответствие в другом языке. При нейросетевом переводе предложение переводится целиком. Оно превращается в векторное пространство, где у каждого слова есть вектор длиной в несколько сотен чисел. Нейросеть определяет взаимосвязь между словами, даже если они находятся в разных концах предложения. Поэтому перевод получается более натуральным.
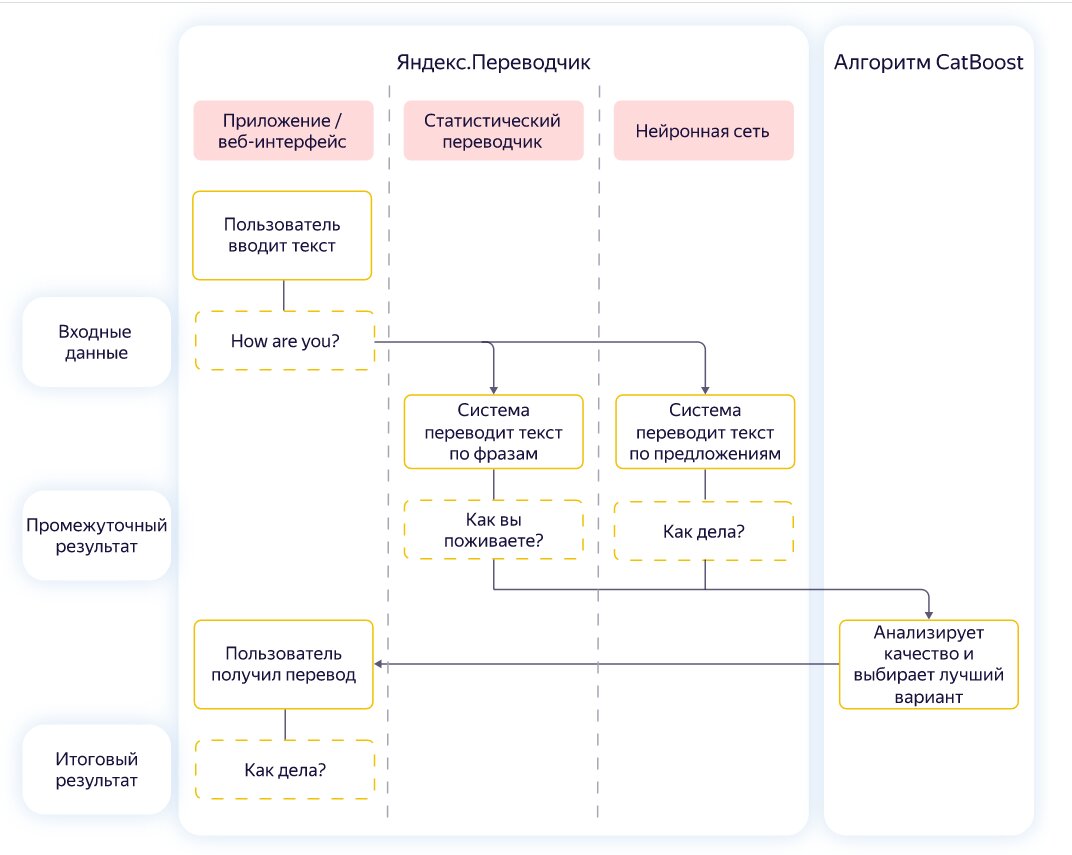
Несмотря на появление нейросетевого подхода, от статистического машинного анализа пока полностью не отказались. Например, в Яндекс.Переводчике используется гибридная модель перевода, которая включает статистический и нейросетевой подходы. После обработки текста двумя моделями в работу включается алгоритм, который выбирает лучший вариант.
Перевод стал лучше, но всё ещё очень много ошибок. Нейросети не справляются?
Количество ошибок в переводе зависит от многих факторов. Среди них — родство языков и объём данных, на которых была обучена нейросеть.
Например, алгоритмы Google Translate обучали на языковых парах «английский — испанский» и «английский — французский». Судя по результатам исследования, профессиональные переводчики оценили качество обработки текста в этих парах почти на уровне человеческого перевода.
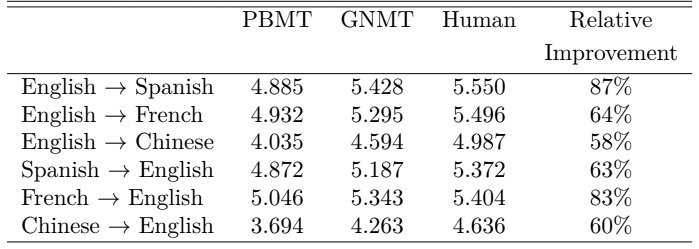
Чем ближе языки друг к другу по структуре, тем выше точность перевода. Но если взять языки из разных систем — например, русский и японский, то здесь универсальные переводчики начинают хромать.
При нейросетевом переводе тоже используется корпус параллельных текстов. Соответственно, сохраняется проблема с нехваткой данных. Если параллельных текстов не хватает для перевода, в ход идёт язык-посредник — английский. Из-за этого возникают неточности. Вы можете сами это легко проверить, если переведёте предложение последовательно на несколько языков.
Например, вот перевод одного из абзацев из этой статьи: русский — английский — монгольский — венгерский — русский. Было так:
«Количество ошибок в переводе зависит от многих факторов. Среди них — родство языков и объём данных, на которых была обучена нейросеть».
Стало так:
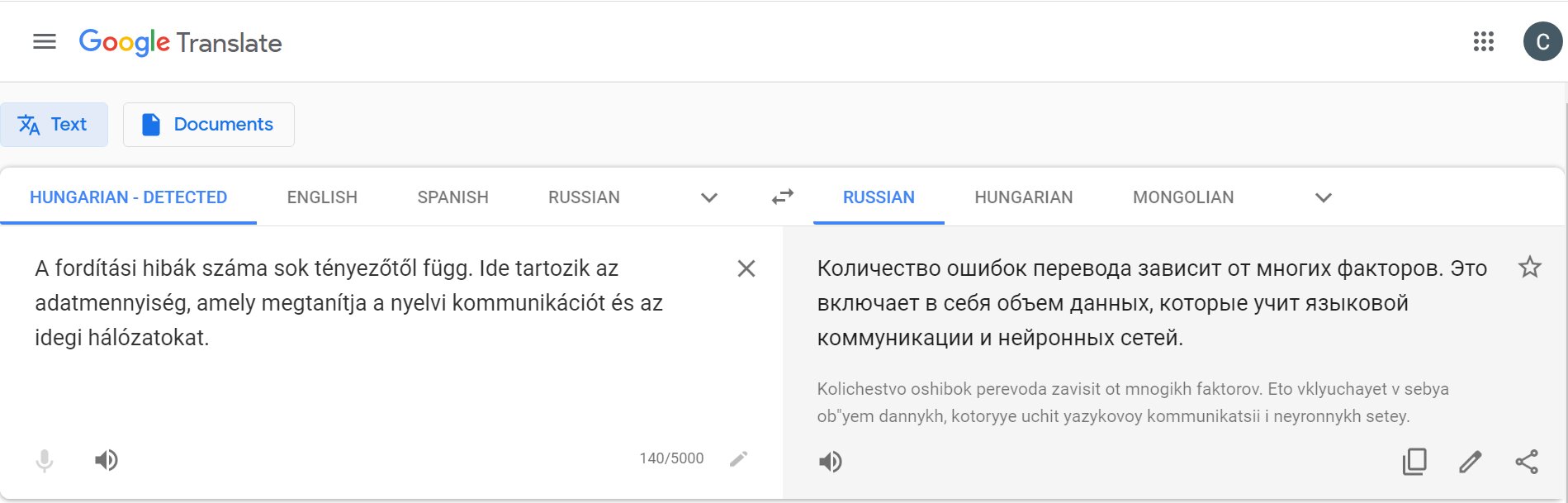
Перевод получился корявым. С другой стороны, это абсолютно бессмысленный эксперимент. Вряд ли в реальной жизни кому-то требуется такая цепочка. Но результаты проверки как раз показывают, что происходит с переводом, когда между языками не хватает параллельных текстов.
Как можно улучшить работу онлайн-переводчиков
По словам разработчиков из команды Яндекса по машинному переводу, один из перспективных путей улучшения качества переводчиков — усиление роли контекста. Он может включать предыдущее предложение, информацию о сущностях и лицах, упомянутых в тексте, сведения о том, из какого места на веб-странице взят фрагмент.
Любой специалист по переводу скажет, что чем больше контекста или справочной информации, тем проще обрабатывать текст. Это легко проверить. Когда вы учите язык и начинаете на нём читать книги или смотреть фильмы, то часть слов понимаете просто из контекста.
Как это работает на примере онлайн-переводчика? Самая очевидная ситуация — система при переводе обращает внимание на предыдущее предложение. Как минимум это позволяет решить проблему с местоимениями. Учитывая контекст предыдущего предложения, переводчик выбирает правильный род для подлежащего или дополнения.
Улучшить качество перевода помогает также добавление в обучающий массив аудио и видео. Сейчас разработчики собирают данные. Например, если в приложении Google Translate запустить режим «Преобразование речи в текст», то появится предупреждение о том, что сделанная вами аудиозапись будет отправлена на обработку в Google. Компания может хранить расшифровку аудио в течение определённого времени в целях улучшения «Переводчика».
Сложность обработки аудиозаписей в том, что в них часто нет контекста. Когда люди разговаривают друг с другом, даже через переводчика, они используют и другие способы коммуникации — например, жестикулируют. Однако добавление аудио всё равно приносит пользу — чем больше данных, тем точнее перевод.
Помогают сделать сервисы лучше и люди. Например, в Яндексе работает группа лингвистической экспертизы, в которую входят редакторы-эксперты и переводчики. Они передают тексты в выборку для машинного обучения.
Google предлагает пользователям стать участниками сообщества «Переводчика», чтобы улучшать качество переводов и добавлять новые языки. Участники сообщества проверяют переводы. Варианты с высокими оценками от специалистов показываются со специальным значком — вы наверняка его видели.
Внести свою лепту в развитие «Google Переводчика» может каждый. Например, можно нажать на кнопку «Редактировать перевод» и предложить свой вариант. Он будет отправлен на рассмотрение участникам сообщества. Если они проголосуют за ваш вариант как за корректный, то он станет основным в переводчике.
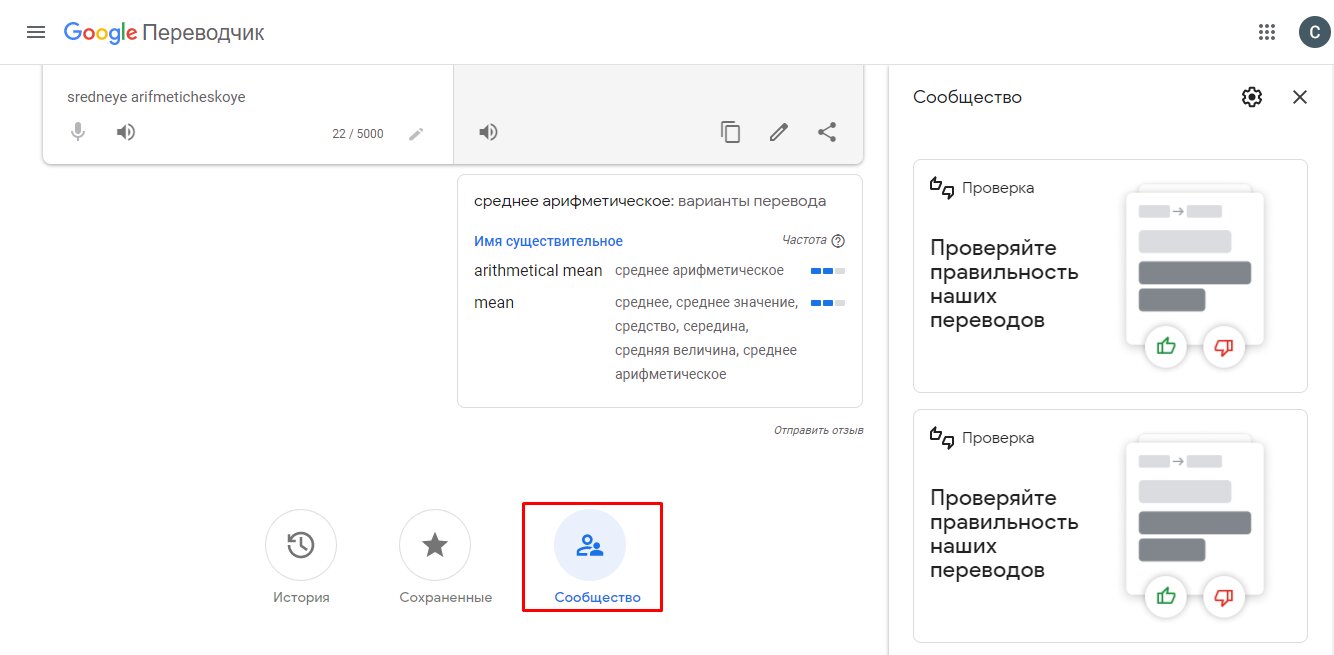
Чтобы голосовать за варианты перевода и добавлять свои фразы, нажмите на кнопку «Сообщество» на главной странице Google Translate. Система предложит выбрать два языка. После этого вы сможете выбирать корректные варианты и делать онлайн-переводчик лучше.
Сейчас работа Google Translate, Яндекс.Переводчика и других подобных сервисов всё ещё кажется неидеальной. Но если оглянуться назад, то они стали переводить тексты намного точнее. По крайней мере, их возможностей уже сейчас достаточно для того, чтобы свободно общаться с носителями разных языков.