DeepSeek придумал необычную оптимизацию ИИ: новая модель V3.2 выбирает только важное из запроса

Разработчики DeepSeek представили новую экспериментальную модель V3.2-exp, созданную для существенной экономии на обслуживание ИИ. Она почти вдвое снижает затраты на вывод информации при использовании в сценариях с длинным контекстом. Ключевой особенностью новой модели является механизм DeepSeek Sparse Attention — система фильтрации, которая выбирает наиболее важное из контекста без потери качества ответов.
DeepSeek V3.2-exp, по сути, использует модуль «молниеносный индексатор» для приоритизации определённых фрагментов из контекстного окна. После этого система точного выбора токенов выбирает из этих фрагментов определённые токены для загрузки в ограниченное окно внимания модуля. Всё это в совокупности позволяет Sparse Attention работать с большими фрагментами контекста при сравнительно небольшой нагрузке на сервер. Для операций с длинным контекстом преимущества системы весьма существенны. Предварительное тестирование DeepSeek показало, что стоимость простого вызова API может быть снижена вдвое. Для более надёжной оценки потребуются дополнительные тестирования.
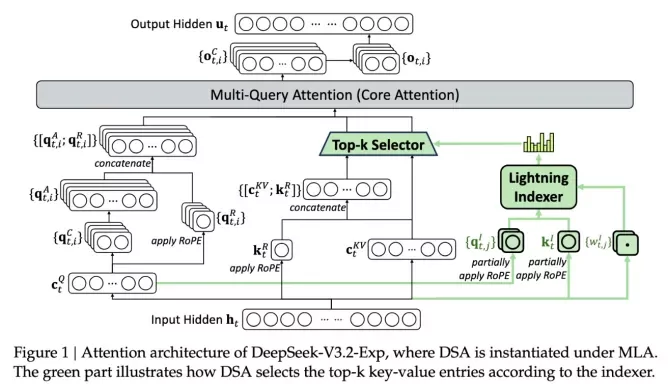
Новая модель DeepSeek — одна из тех, что направлены на решение проблемы затрат на работу предварительно обученной ИИ-модели. В бенчмарках она не уступает предыдущей версии, а в тестах на рассуждение и кодирование разница совсем незначительная. Модель работает в 2-3 раза быстрее, меньше потребляет память и вдвое эффективнее. Такой подход с «рассеянным вниманием» может подтолкнуть других разработчиков взять на вооружение этот приём, чтобы снизить затраты на обслуживание ИИ.
И это шутка только наполовину, потому что новая Клауди 4.5 от Антропик уже научилась определять, когда ее тестируют в бенчмарках, и подгонять свои ответы именно под бенчмарк