
Сбер опубликовал в открытом доступе экспериментальную диффузионную языковую модель GFusion и метод её обучения, сообщили редакции Трешбокс.ру в пресс-службе компании. В отличие от классических LLM, которые генерируют текст последовательно — слово за словом, — GFusion сначала создаёт приблизительный «набросок» ответа, а затем пошагово его дорабатывает. Такой подход устраняет жёсткую привязку к порядку слов и позволяет модели самой выбирать, какую часть ответа улучшить на каждом шаге.
Автор проекта — Даниил Тихонов. В момент создания модели он был стажёром в команде фундаментальных моделей Сбера и студентом 4-го курса Факультета компьютерных наук НИУ ВШЭ. Сейчас Даниил успешно защитил диплом и работает в штате банка.
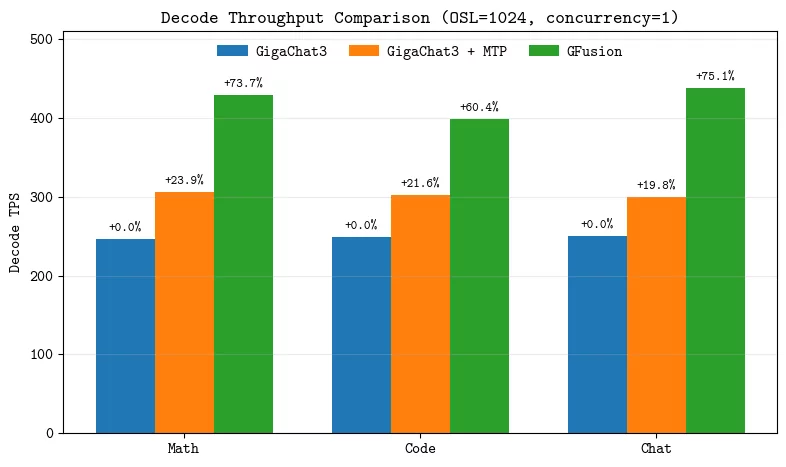
По тестам Сбера GFusion генерирует текст до 45% быстрее GigaChat 3, на основе которого обучалась. Достигается это за счёт того, что токены генерируются не по одному, а сразу пачками. Среди других особенностей модели:
— нелинейная генерация: текст не обязан идти строго слева направо;
— повышенная эффективность обучения: модель может проходить по одному и тому же датасету несколько раз, извлекая больше информации из ограниченного объёма данных.
Вместе с моделью Сбер выложил инструменты для ускорения обучения диффузионных языковых моделей. Это первый такой опенсорс-проект в России, утверждают в компании. Кроме того, команда внесла изменения в SGLang — популярный опенсорс-инструмент для запуска языковых моделей, — добавив в него поддержку GFusion и нового алгоритма генерации, который улучшает качество любых dLLM.
«Диффузионные модели лучше структурируют ответы и могут генерировать текст непоследовательно, самостоятельно выбирая порядок написания. Они эффективнее используют ограниченный объём данных при обучении. Это пока открытое направление, и мы надеемся, что GFusion даст другим командам рабочую точку отсчёта», — прокомментировал Даниил Тихонов.
В Сбере отмечают, что активное развитие диффузионных языковых моделей идёт с конца 2025 года. Сегодня такие модели уже применяются для автодополнения кода в реальном времени, агентных сценариев и в приложениях, критичных к задержкам. Приоритетной задачей остаётся выведение качества ответов и способности к рассуждению на уровень классических LLM.