
Вчера, 15 апреля, компания Google официально представила Gemini 3.1 Flash TTS — новейшую модель искусственного интеллекта, отвечающую за преобразование текстового контента в речь. Ключевой особенностью данной новинки можно смело назвать систему аудиотегов — это новый способ управления стилем, темпом и манерой сгенерированной речи.
«Встраивая команды непосредственно в текстовый инпут, вы можете управлять выводом речи с гораздо большей точностью», — заявили представители поискового гиганта.
И выглядит эта система действительно очень гибкой — например, пользователь может срежиссировать сцену, подобрав оптимальные параметры для более точной генерации. Можно определить окружение сцены и дать конкретные установки по проведению диалога, чтобы получить необходимый результат.
«Контекст, создающий мир, помогает персонажам оставаться в образе и естественно реагировать друг на друга на протяжении нескольких ходов», — объяснили представители Google.
Кроме того, пользователь может задействовать уникальные аудиопрофили для подбора «актёров озвучки», а затем указывать примечания со стороны «режиссёра». Это позволяет менять темп, тон и даже акцент говорящего, а встроенные теги позволяют переключаться между базовыми настройками генерации даже посреди предложения. И, что самое интересное, когда пользователь настроит генерацию под свои требования, он может экспортировать точные параметры в виде кода API Gemini, чтобы затем использовать эти же параметры генерации аудио в других своих проектах. Это очень важно для согласованности конечного контента.
Также представители поискового гиганта делают акцент на том, что в Gemini 3.1 Flash TTS было существенно улучшено качество генерации речи. Более того, представители компании даже заявили, что их модель является самой естественной и выразительной моделью в этом сегменте на текущий момент. Эти заявления подкрепляются результатами слепых тестов бенчмарка Artificial Analysis TTS — новинка на данный момент набрала 1211 баллов, существенно оторвавшись от ElevenLabs v3 (одна из лучших моделей преобразования текста в речь).
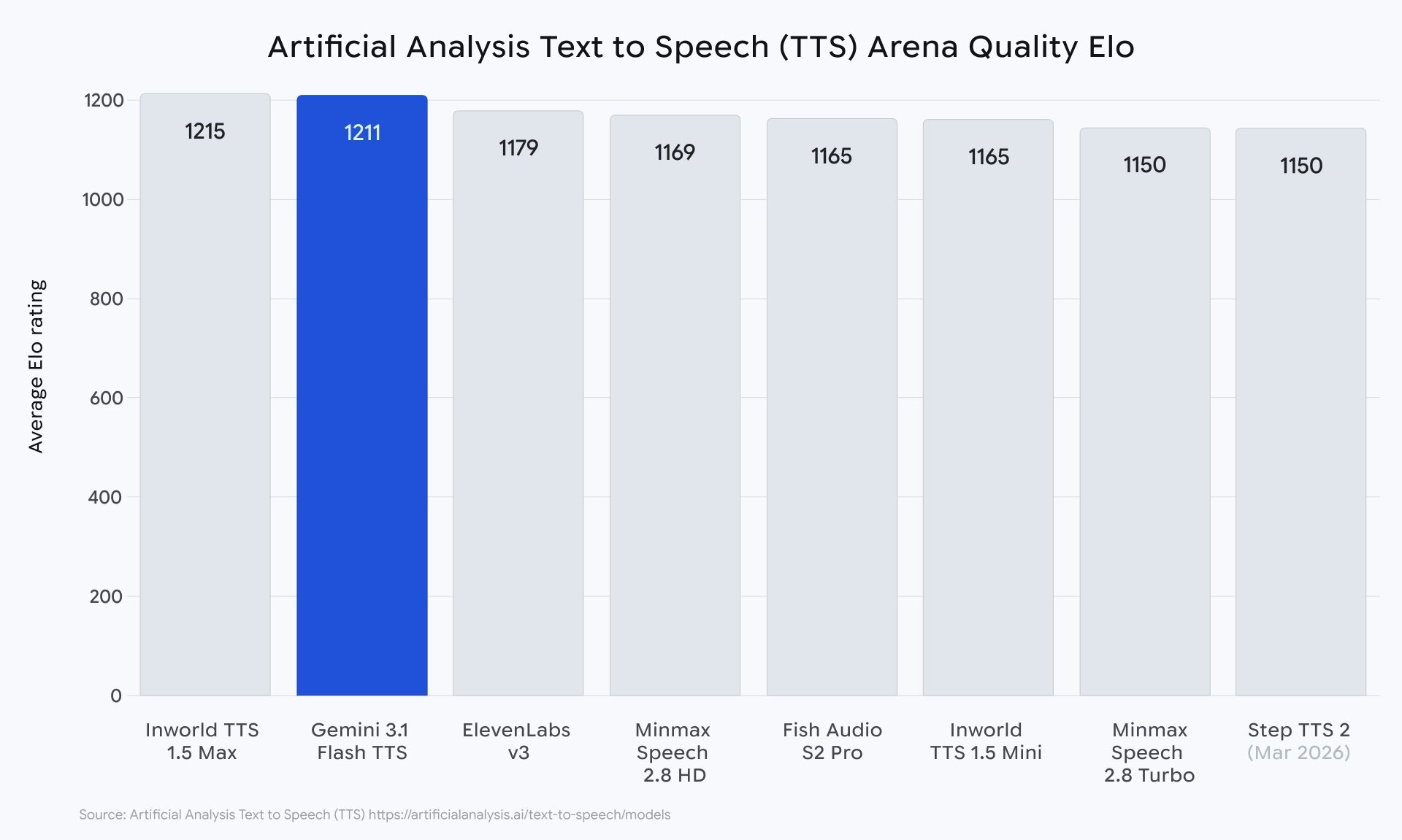
При этом первое место в рейтинге новинка занять всё же не смогла — Inworld TTS 1.5 Max опережает разработку Google на 4 балла. Разрыв не такой уж и большой, плюс стоит сказать, что поисковой гигант ворвался в ИИ-гонку с отставанием от конкурентов, так что данные результаты всё равно впечатляют.