Тест современных нейросетей: насколько топовые LLM начинают «тупить» при увеличении числа инструкций

Два дня назад, 15 июля, Даниэль Ярославич (Daniel Jaroslawicz), преподаватель Колумбийского университета Нью-Йорка и сотрудник американского стартапа Distyl AI, совместно с командой специалистов опубликовал на портале arXiv довольно интересное исследование, затрагивающее возможность больших языковых моделей (в том числе промышленного уровня) справляться с выполнением десятков или даже сотен инструкций одновременно. В рамках данного исследования авторы отмечают, что на данный момент возможности LLM в рамках выполнения задач при высокой плотности инструкций ещё не изучены, поскольку современные тесты в большинстве своём оценивают модели только на задачах с одной или несколькими инструкциями.
Для того, чтобы оценить текущие LLM при большом количестве инструкций, команда специалистов разработала бенчмарк IFScale — он представляет собой простой тест с 500 инструкций и позволяет оценить, как производительность выполнения инструкций снижается с ростом плотности этих самых инструкций.
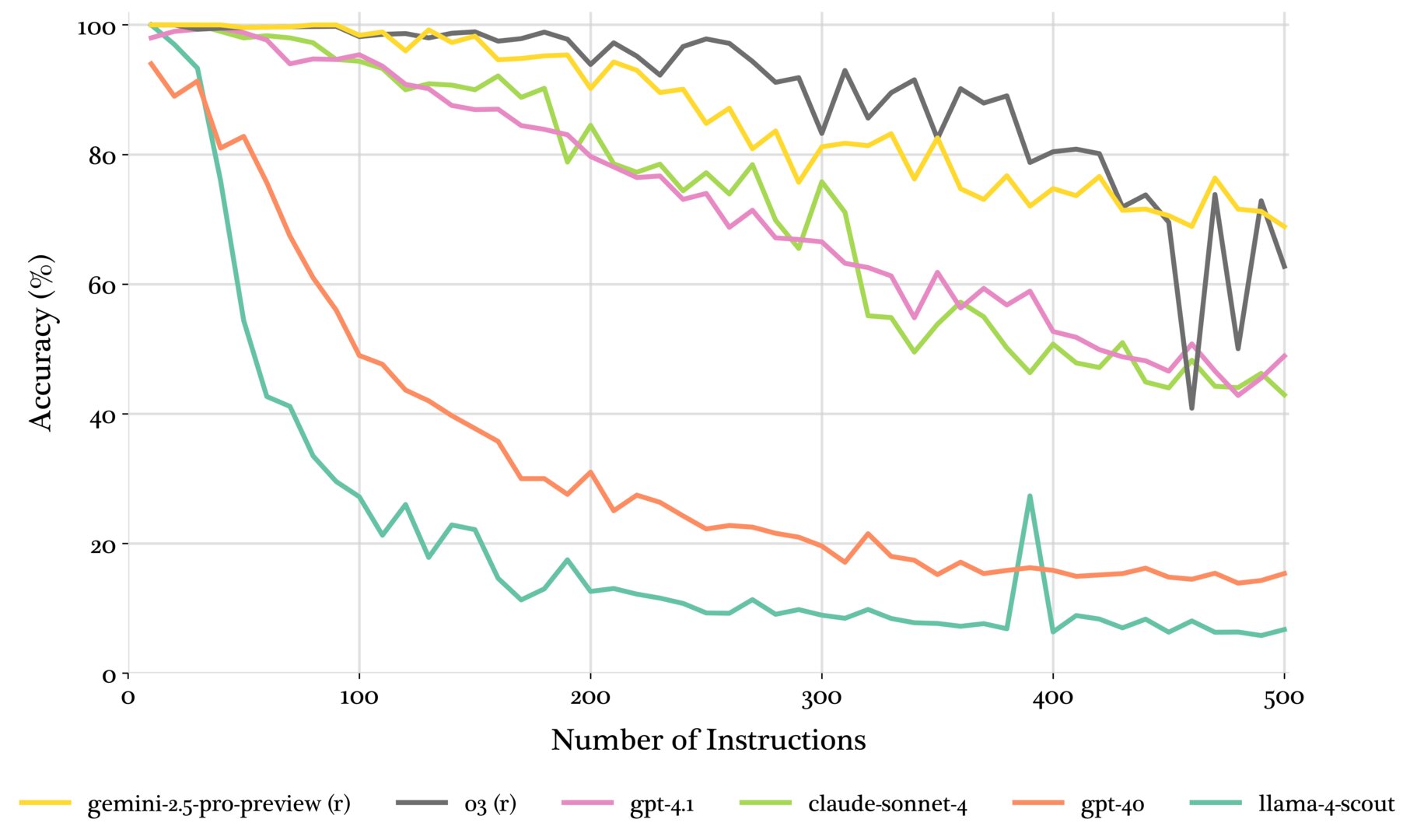
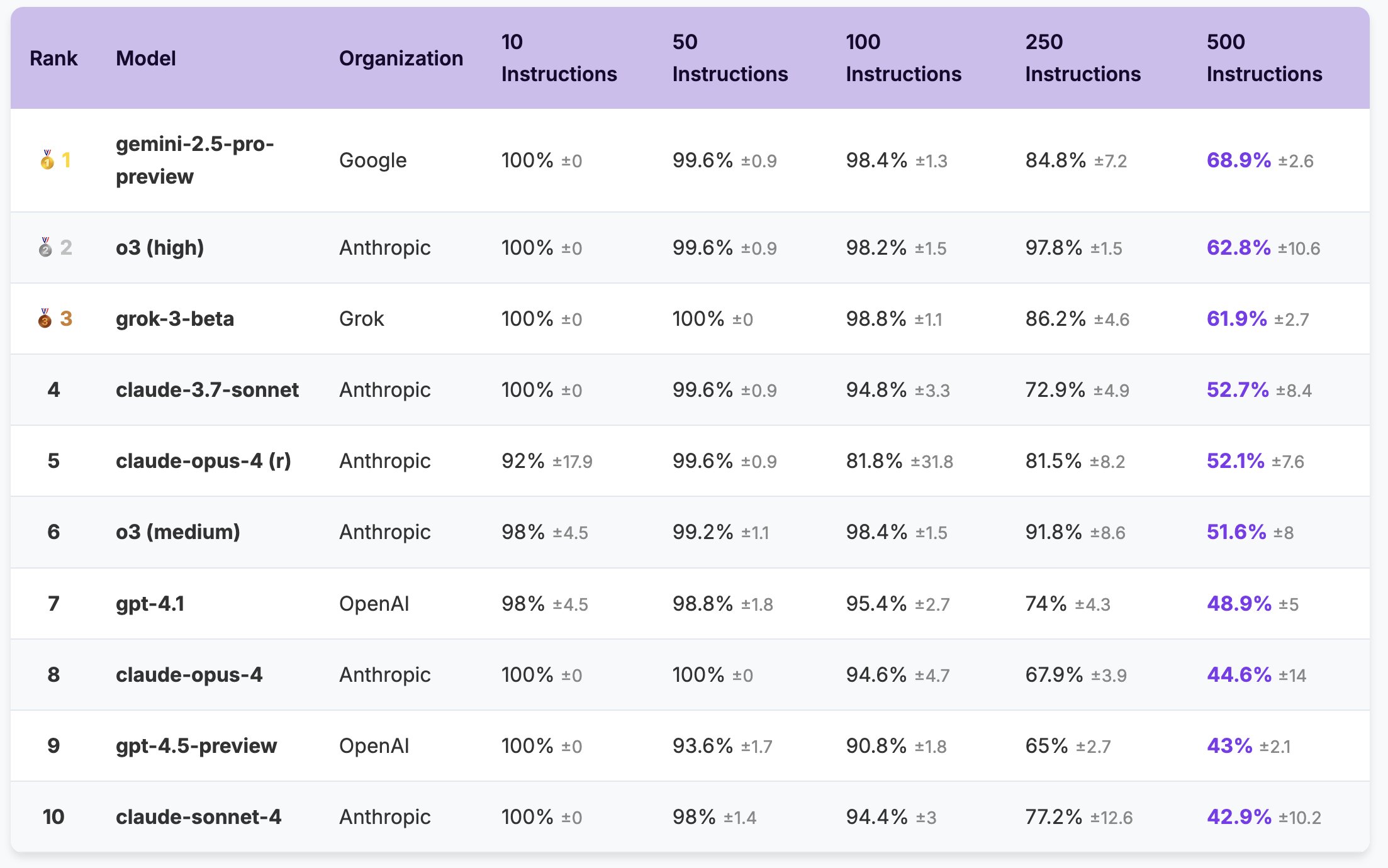
Также авторы проекта прогнали через свой бенчмарк сразу 20 современных больших языковых моделей от семи крупных разработчиков на рынке, обнаружив, что даже передовые модели демонстрируют точность всего лишь в 68% при максимальной плотности в 500 инструкций. Более того, если посмотреть на результаты тестов, то можно заметить, что некоторые модели уходят ниже 100% точности даже при 10 инструкциях, не справляясь с нагрузкой.
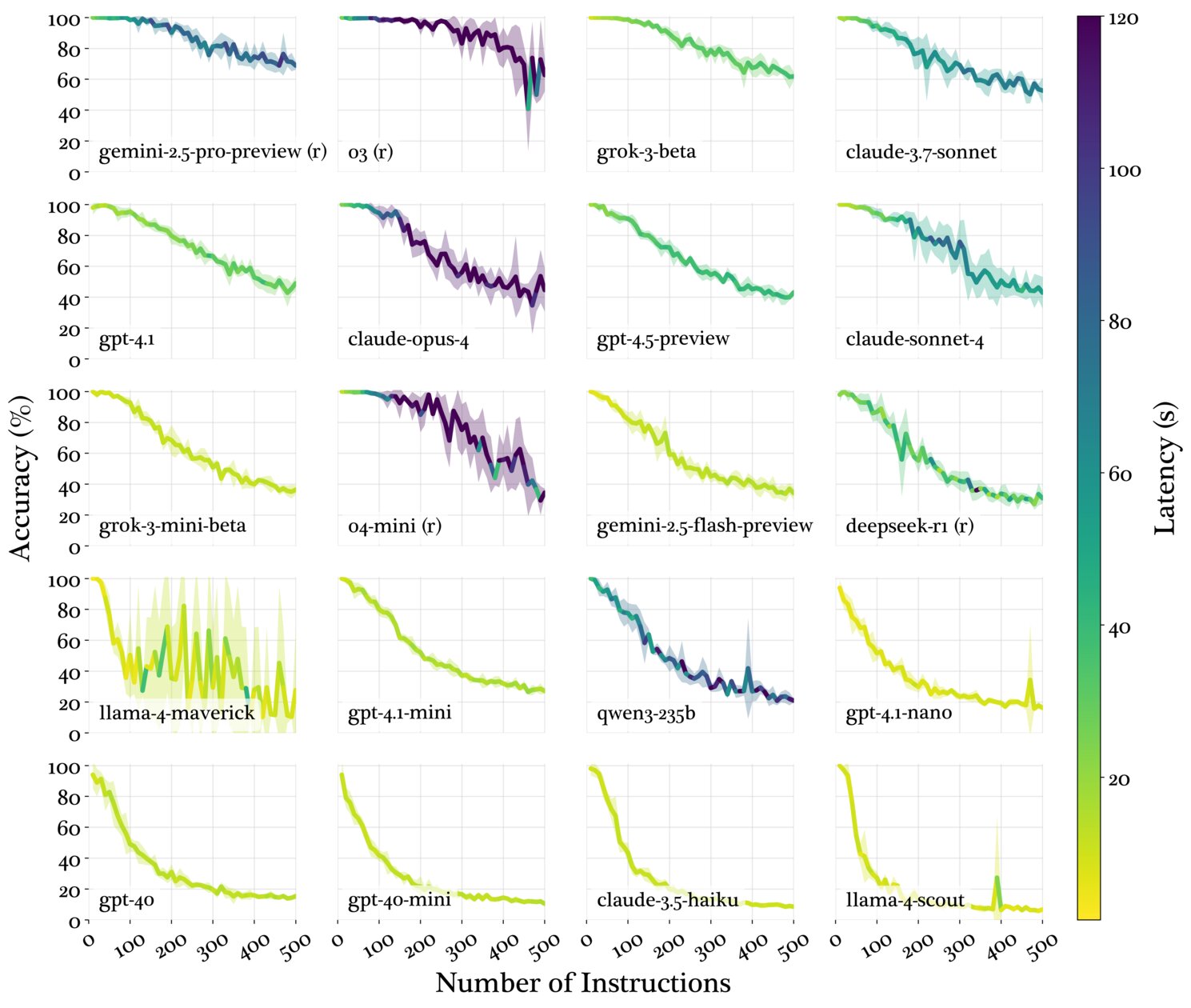
Ещё специалистам в рамках данного анализа удалось выяснить, что размер модели и её способность к рассуждению коррелируют с тремя определёнными паттернами снижения производительности LLM — смещением в сторону более ранних инструкций и различными категориями ошибок при выполнении инструкций.
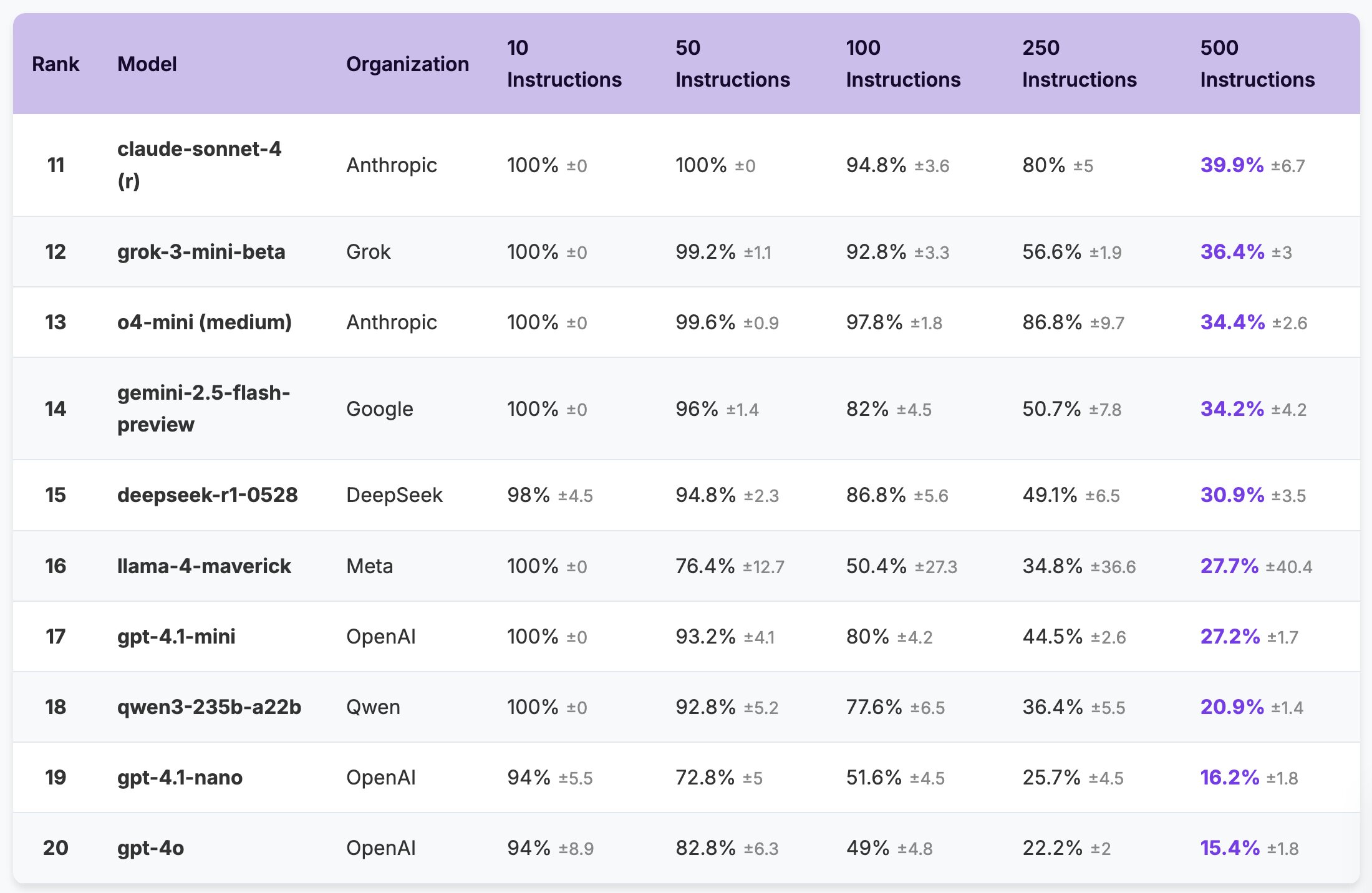
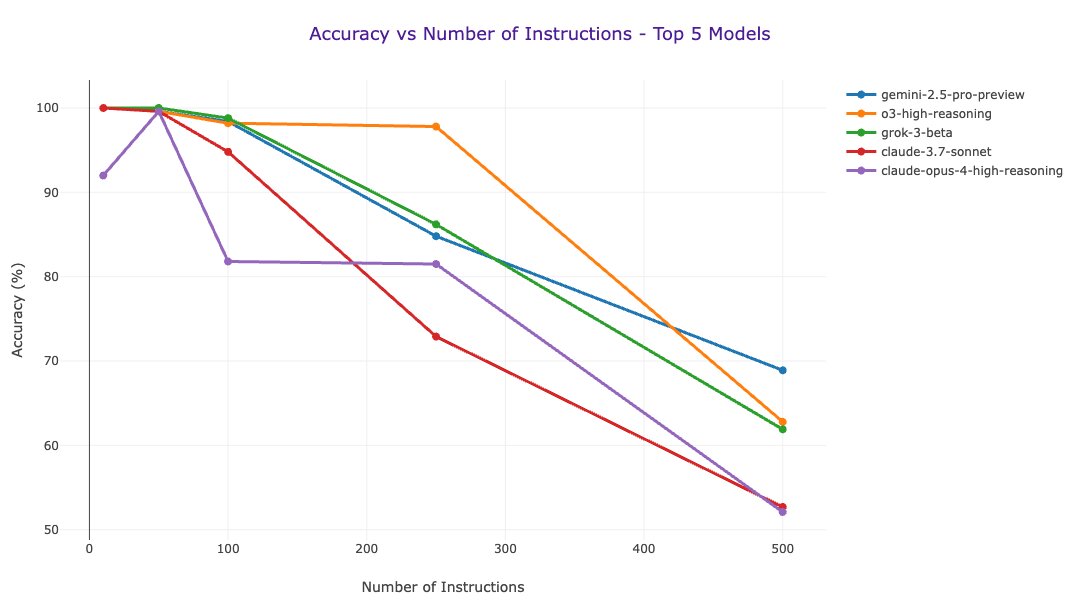
Например, им удалось определить, что модели рассуждений как правило превосходят по производительности свои универсальные аналоги — они сохраняют практически идеальную производительность при умеренной плотности инструкций (в диапазоне 100-250). Кроме того, что вполне ожидаемо, универсальные модели нового поколения чаще всего превосходят по производительности свои аналоги прошлых поколений, а более крупные модели превосходят мелкие.
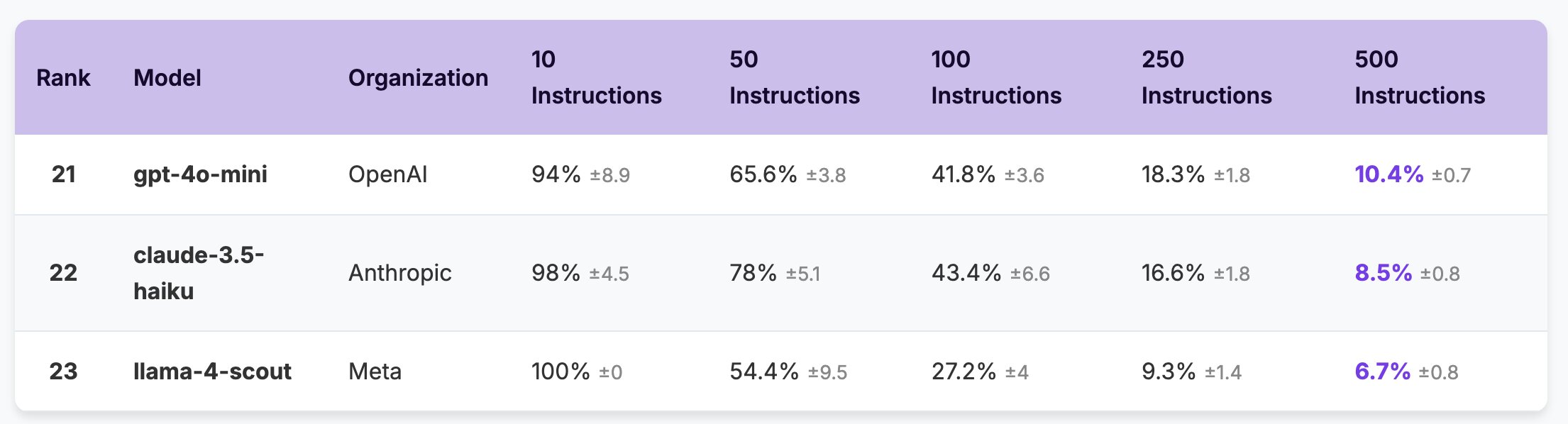
Результаты тестов в бенчмарке IFScale, по словам авторов исследования, помогут в разработке решений с высокой плотностью инструкций в реальных приложениях, а также выявить важные компромиссы между общей производительностью и задержкой. К счастью, доступ к результатам тестов доступен всем желающим — авторы проекта опубликовали исходный код теста и все финальные данные.