
Внедрение генеративных моделей за последние несколько лет произвело революцию в области искусственного интеллекта. Это привело к тому, что генерировать изображения, видео- и аудиоконтент стало лучше и быстрее. И если проблем с выбором инструментов для создания изображений и видео на текущий момент особых нет, то с аудио ситуация немного сложнее. Компания Stability AI, которая разработала ИИ-технологию Stable Diffusion для преобразования текста в изображение, представила новую нейросеть Stable Audio. Она предназначена для генерации коротких аудиотреков по текстовому описанию и базируется на тех же принципах работы, что и Stable Diffusion.
Одна из основных проблем при создании аудиокомпозиции с использованием моделей диффузии заключается в том, что они обычно обучаются генерировать выходные данные фиксированного размера. Например, нейросеть может быть обучена на 30-секундных звуковых фрагментах и генерирует только треки такой же длительности. Это проблема при обучении и создания композиций различной длины. Кроме того, модель генерирует произвольные фрагменты, которые могут резко начинаться или обрываться.
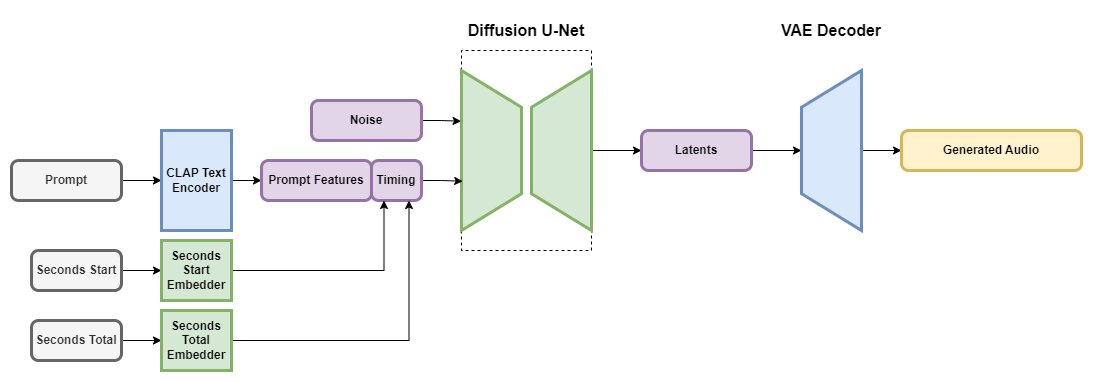
Stable Audio руководствуется текстовыми метаданными, а также продолжительностью аудиофайла и начальным временем. Всё это позволяет контролировать содержимое и длину сгенерированного звукового файла. Языковая модель способна обрабатывать 95 секунд стереозвука с частотой дискретизации 44,1 кГц менее чем за одну секунду на графическом процессоре NVIDIA A100. Она использует Descript Audio Codec, что позволяет кодировать и декодировать звук произвольной длины, а также получать высококачественные выходные данные. Помимо этого, используется модель CLAP, обученная с нуля на наборе данных Stability AI, что позволяет текстовым данным содержать некоторую информацию о связях между словами и звуками.
Для обучения Stable Audio компания задействовала набор данных, состоящий из более чем 800 тыс. аудиофайлов: музыка, звуковые эффекты, отдельные инструменты, а также соответствующие текстовые метаданные. Это более 19 500 часов аудио. Нейросеть имеет около 1,2 млрд параметров, примерно столько же есть и у Stable Diffusion.
Stable Audio доступна в двух вариантах: бесплатном (до 20 треков в месяц продолжительностью до 45 секунд) и платном стоимостью 12 долларов (до 500 треков в месяц продолжительностью до 90 секунд).