
Вчера, 7 августа, компания OpenAI представила миру новую линейку моделей искусственного интеллекта под названием GPT-5, рассказав пользователям о преимуществах свежей LLM в различных сферах применения ИИ. И, естественно, чтобы более наглядно продемонстрировать ключевые особенности большой языковой модели, американский гигант в рамках мероприятия показал несколько диаграмм, сравнивая показатели GPT-5 с предыдущими ИИ-моделями в различного рода бенчмарках. Эти графики, естественно, выглядели весьма впечатляюще, но если присмотреться к данным, указанным на «столбиках» диаграмм, могут возникнуть определённые вопросы.
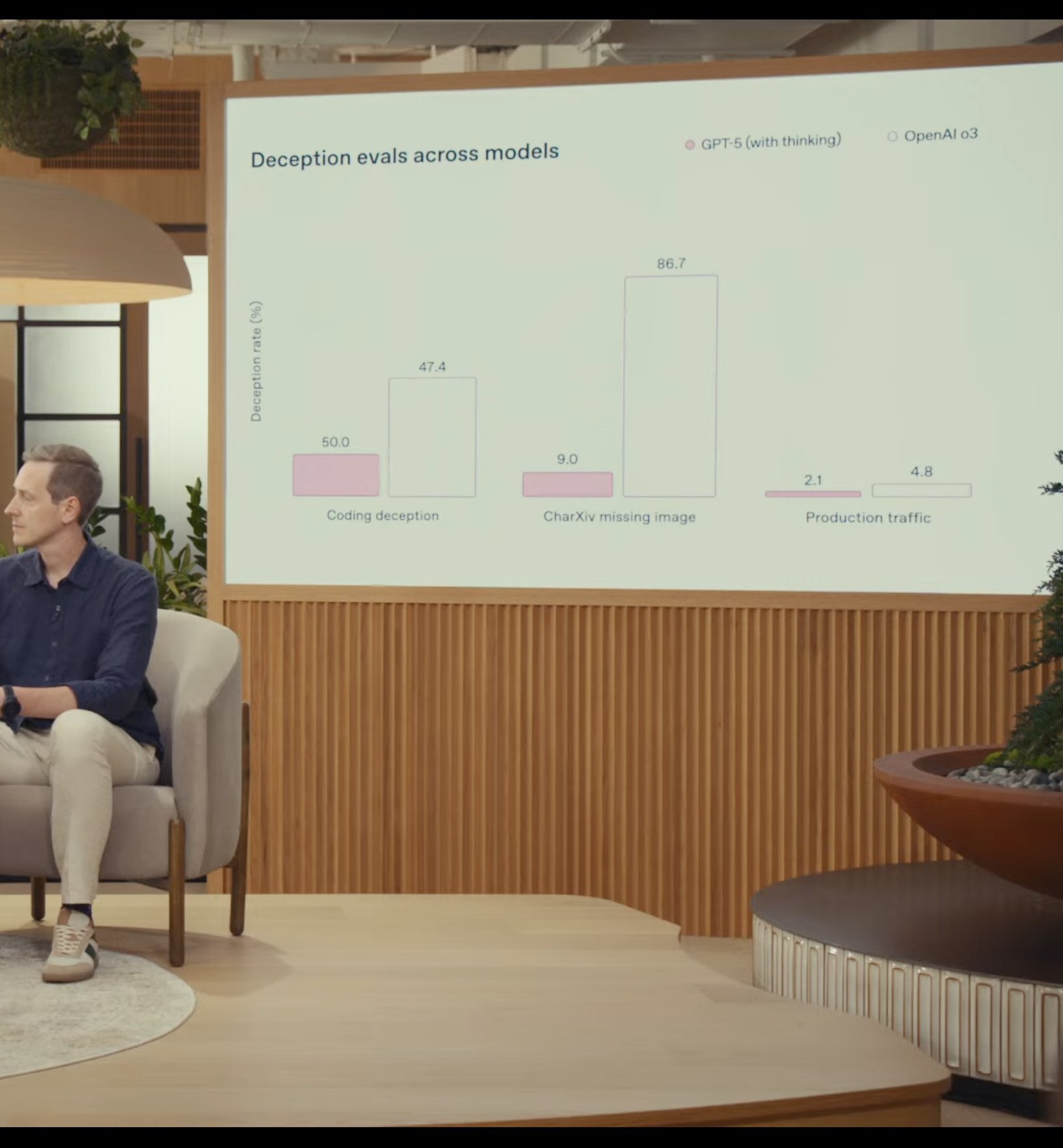
Например, на одном из слайдов с заголовком Deception evals across models («Оценка ложных ответов для разных моделей») можно заметить очень странную шкалу с подписью Coding deception («Ложные ответы при программировании») — на ней указано, что GPT-5 с режимом размышлений демонстрирует 50% ошибок, а OpenAI o3 набирает 47,4%. Вот только столбик с розовой заливкой, принадлежащий GPT-5, гораздо короче, чем у OpenAI o3, хотя на деле он должен быть выше, так как модель, судя по указанным данным, ошибается чаще LLM o3. Эту ошибку вполне можно было бы списать на человеческий фактор, вот только это не единственный пример в презентации.
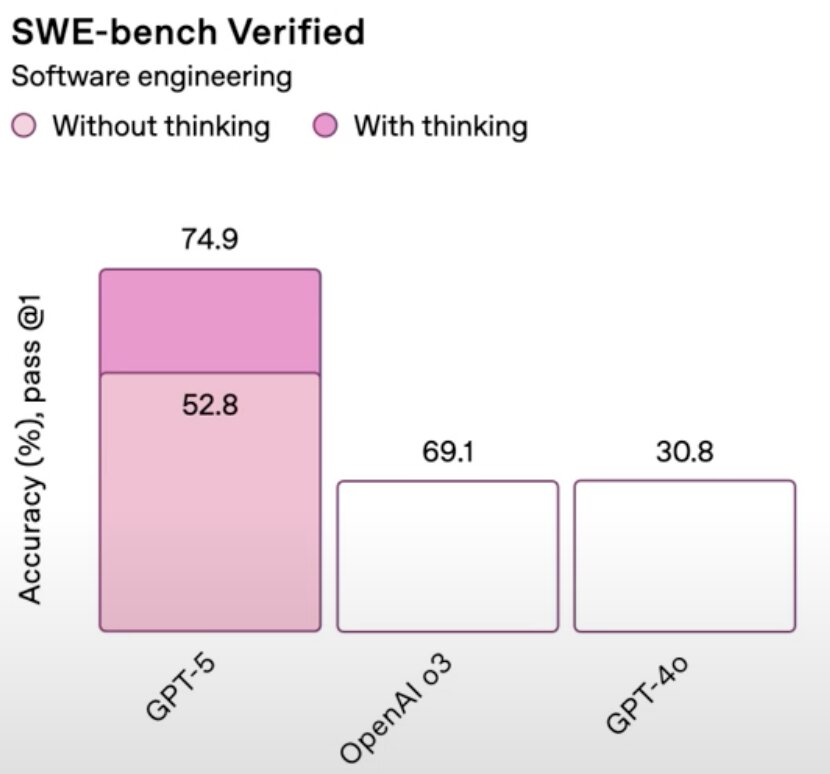
На одном из последующих слайдов был представлен график сравнения результатов GPT-5, OpenAI o3 и GPT-o4 в бенчмарке Software engineering, который оценивает возможности моделей искусственного интеллекта в области программирования. На этом графике чётко видно, что GPT-5 без режима размышлений набирает 52,8% точных ответов, тогда как OpenAI o3 демонстрирует 69,1%, а GPT-o4 — всего 30,8%. Правда, столбик GPT-5 оказался выше OpenAI o3, при этом OpenAI o3 и GPT-o4, судя по изображению, выглядят абсолютно идентично, хотя разница в точности между ними ровно в два раза. Собственно, ошибка была настолько заметной, что даже Сэм Альтман в ходе презентации был вынужден извиниться, пообещав исправить проблему в официальном блоге.
Стоит сказать, что на официальном сайте данные действительно исправили (сразу после того, как в социальных сетях разразился настоящий скандал), так что теперь графики выглядят корректно, но впечатление от мероприятия эти ошибки, безусловно, подпортили. Особенно на фоне того, что представители OpenAI активно расхваливали повышенную точность GPT-5 и снижение галлюцинаций искусственного интеллекта.